
Bekerja menggunakan data seperti pencampuran antara art dan science. Tetapi orang lebih fokus untuk membahas pada sisi sciencenya saja. Pada kesempatan ini kita akan belajar dari sisi seninya.
Exploratory Data Analysis (EDA)
Setelah anda mementukan pertanyaan apa yang ingin anda jawab dan anda sudah memiliki data yang anda butuhkan. Kemungkinan besar anda sangat ini untuk langsung membangun model machine learning dan mendapatkan jawaban dari pertanyaan anda. Tetapi langkah pertama yang perlu anda lakukan adalah mengeksplorasi data yang anda miliki.
Eksplorasi data satu dimensi
Eksplorasi data satu dimensi adalah proses analisis yang bertujuan untuk memahami karakteristik dan pola dari sekumpulan data yang memiliki satu atribut atau variabel. Dalam eksplorasi ini, data biasanya disajikan dalam bentuk grafik, tabel, atau statistik deskriptif yang menggambarkan distribusi, tendensi, dan variasi data tersebut.
Kasus yang paling sederhana adalah ketika anda berhadapan dengan data dengan tipe satu dimensi, yang pada dasarnya adalah sebuah kumpulan angka. Misalnya, kumpulan data pengunjung dari website yang anda miliki, kumpulan data sampai halaman berapakah buku yang sedang anda baca, atau kumpulan waktu tayang dari video tutorial data science yang anda lihat di YouTube.
Seperti biasa yang perlu anda ketahui adalah mencari tahu beberapa hal. Anda perlu mencari tahu berapa banyak data yang anda miliki, berapakah data terkecilnya, berapakah data terbesarnya, berapakah mean, dan yang terakhir berapakah standar deviasinya.
Tetapi jika hal-hal tadi sudah anda lakukan dan anda masih belum mendapatkan gambaran jelas tentang data yang anda miliki, anda bisa menggunakan histogram untuk membantu anda dalam memahami karakteristik data yang anda miliki.
Eksplorasi data dua dimensi
Eksplorasi data dua dimensi adalah sebuah proses analisa yang bertujuan untuk memahami karakter dan pola dari sebuah data yang memiliki atribut dua variable. Untuk bisa mengekstrak informasi dari data dua dimensi biasanya data disajikan dalam bentuk scatter plot, histogram, dan cross tabulation.
Sekarang bayangkan misalnya anda memiliki sebuah data dua dimensi dan anda ingin mengetahui trend dari data yang anda miliki. Jika anda menggunakan histogram, maka akan dihasilkan sebuah visualisasi yang datar dan tampak sulit untuk dibedakan. Akan berbeda kasusnya jika anda menggunakan scatter plot, perbedaan variable antar data dapat lebih mudah dipahami jika menggunakan visualisasi yang tepat.
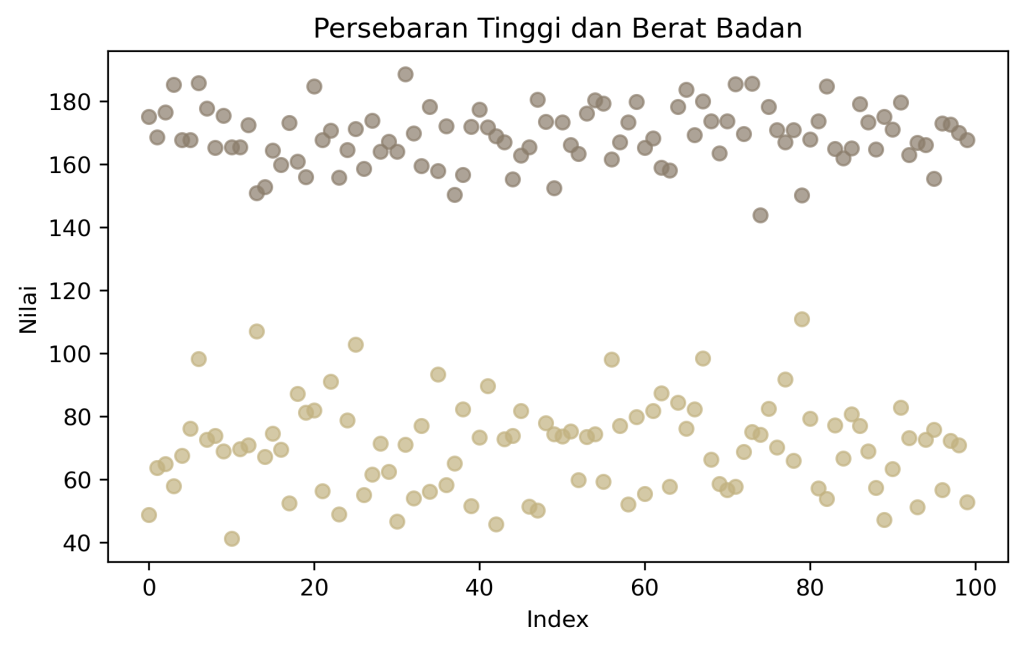
Eksplorasi data multidimensi
Singkatnya eksplorasi data multidimensi merupakan sebuah upaya untuk memahami data dari berbagai variable. Nah tujuannya sendiri itu untuk cari pola, keteraturan, hubungan, atau insight dari sebuah dataset yang kalau dilihat dari satu atau dua variable aja ngga akan kelihatan.
Dengan banyaknya dimensi yang ingin anda perhatikan, cara terbaik untuk melihat hubungan antar variable adalah dengan melakukan visualisasi menggunakan correlation matrix. Yang cara membacanya sangat sederhana misalnya kita memiliki baris a dan kolom b, pada correlation matrix menggambarkan hubungan antara baris a dan juga kolom b. Pada correlation matrix memiliki nilai diantara -1 hingga 1. Dimana -1 artinya hubungan yang ditimbulkan saling bertolak belakang, sedangkan 1 dinyatakan ditemukan hubungan yang kuat antar variable dan 0 tidak ditemukan hubungan.
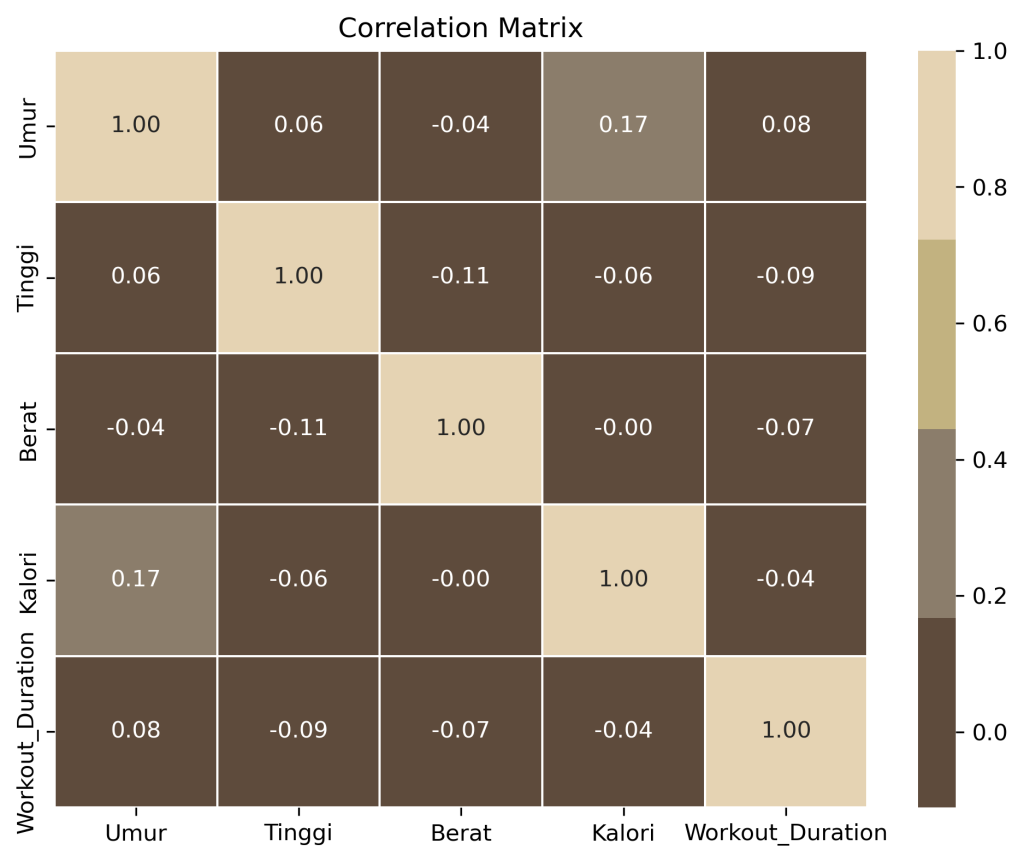
Cara handle data
Menggunakan NamedTuples
Salah satu trick kecil yang bisa digunakan dalam mempermudah pekerjaan data science anda adalah dengan menggunakan package namedtuple, dengan menggunakan package ini anda bisa memberikan label dari data yang anda gunakan misalnya seperti ini.
data = ("Febrian", 25)
print(data[0]) # bingung ini apa yang diprint?Jika anda ingin memberikan label dari data yang anda gunakan, anda bisa menggunakan namedtuple, dan hasilnya akan seperti ini.
from collections import namedtuple
Person = namedtuple("Person", ["name", "age"])
p = Person("Febrian", 25)
print(p.name) # jelas banget bahwa yang diprint merupakan nama dan umur
print(p.age)Data classes
Buat point selanjutnya sebenernya tidak terlalu fundamental gitu sih, cuma misal mau dipakai coding yang kalian tulis bakal lebih rapi dan ringkas aja. Metode yang dimaksud adalah data classes, data classes adalah sebuah metode untuk menyimpan data,tujuannya adalah agar tidak menulis ulang data secara berulang – ulang. Kita langsung masuk ke contoh coding aja ya.
import re
from typing import List
# fungsi cleaning
def clean_text(text: str) -> str:
text = text.lower()
text = re.sub(r"http\S+", "", text)
text = re.sub(r"[^a-zA-Z\s]", "", text)
return text.strip()
# fungsi sentiment
def simple_sentiment(text: str) -> str:
positive_words = ["good", "great", "happy", "love", "awesome"]
negative_words = ["bad", "sad", "hate", "terrible", "angry"]
score = 0
for word in positive_words:
if word in text:
score += 1
for word in negative_words:
if word in text:
score -= 1
if score > 0:
return "positive"
elif score < 0:
return "negative"
else:
return "neutral"
# CLASS BIASA
class Tweet:
def __init__(self, id, username, raw_text):
self.id = id
self.username = username
self.raw_text = raw_text
# manual isi field tambahan
self.cleaned_text = clean_text(raw_text)
self.sentiment = simple_sentiment(self.cleaned_text)
def word_count(self):
return len(self.cleaned_text.split())
def is_long_tweet(self):
return self.word_count() > 10
# =========================
# DATA
# =========================
tweets_data = [
{"id": 1, "username": "user1", "text": "I love this product! It's awesome 😍"},
{"id": 2, "username": "user2", "text": "This is bad, I hate it"},
{"id": 3, "username": "user3", "text": "It's okay, nothing special"},
]
tweets: List[Tweet] = []
for data in tweets_data:
tweet = Tweet(
id=data["id"],
username=data["username"],
raw_text=data["text"]
)
tweets.append(tweet)
# =========================
# OUTPUT
# =========================
for t in tweets:
print("ID:", t.id)
print("User:", t.username)
print("Raw:", t.raw_text)
print("Cleaned:", t.cleaned_text)
print("Sentiment:", t.sentiment)
print("Word Count:", t.word_count())
print("Long Tweet:", t.is_long_tweet())
print("-" * 40)Bandingkan dengan code yang menggunakan data classes, Dibawah ini adalah code yang menerapkan data classes.
from dataclasses import dataclass, field
from typing import List
import re
# fungsi sederhana buat cleaning text
def clean_text(text: str) -> str:
text = text.lower()
text = re.sub(r"http\S+", "", text) # hapus link
text = re.sub(r"[^a-zA-Z\s]", "", text) # hapus simbol
return text.strip()
# fungsi simple sentiment (rule-based)
def simple_sentiment(text: str) -> str:
positive_words = ["good", "great", "happy", "love", "awesome"]
negative_words = ["bad", "sad", "hate", "terrible", "angry"]
score = 0
for word in positive_words:
if word in text:
score += 1
for word in negative_words:
if word in text:
score -= 1
if score > 0:
return "positive"
elif score < 0:
return "negative"
else:
return "neutral"
# DATA CLASS
@dataclass
class Tweet:
id: int
username: str
raw_text: str
cleaned_text: str = field(init=False)
sentiment: str = field(init=False)
def __post_init__(self):
# otomatis jalan setelah object dibuat
self.cleaned_text = clean_text(self.raw_text)
self.sentiment = simple_sentiment(self.cleaned_text)
def word_count(self) -> int:
return len(self.cleaned_text.split())
def is_long_tweet(self) -> bool:
return self.word_count() > 10
# =========================
# SIMULASI DATA
# =========================
tweets_data = [
{"id": 1, "username": "user1", "text": "I love this product! It's awesome 😍"},
{"id": 2, "username": "user2", "text": "This is bad, I hate it"},
{"id": 3, "username": "user3", "text": "It's okay, nothing special"},
]
# convert ke object data class
tweets: List[Tweet] = []
for data in tweets_data:
tweet = Tweet(
id=data["id"],
username=data["username"],
raw_text=data["text"]
)
tweets.append(tweet)
# =========================
# ANALISIS
# =========================
for t in tweets:
print("ID:", t.id)
print("User:", t.username)
print("Raw:", t.raw_text)
print("Cleaned:", t.cleaned_text)
print("Sentiment:", t.sentiment)
print("Word Count:", t.word_count())
print("Long Tweet:", t.is_long_tweet())
print("-" * 40)
# =========================
# SUMMARY
# =========================
positive = sum(1 for t in tweets if t.sentiment == "positive")
negative = sum(1 for t in tweets if t.sentiment == "negative")
neutral = sum(1 for t in tweets if t.sentiment == "neutral")
print("Summary:")
print("Positive:", positive)
print("Negative:", negative)
print("Neutral:", neutral)Apa sih perbedaannya? Jika tanpa data classes kamu harus menulis _init_ secara manual, lalu memasukkan semua atribut satu persatu, dengan menggunakan data classses kita bisa menulis code dengan lebih rapi. Dengan menggunakan data classes anda bisa auto generate (_init_, _repr_ dan_eq_). Sisanya adalah tinggal fokus untuk menyusun logika saja.
Data cleaning
Data yang akan anda kerjakan pada umumnya merupakan data yang masih mentah dan sangat kotor, anda perlu menyisihkan banyak waktu untuk membersihkan data hingga benar benar siap untuk digunakan. Langkah pertama dalam melakukan data cleaning adalah mengetahui tujuan anda melakukan analisa data. Setelah anda mengetahui tujuan anda, tentukan data yang anda butuhkan, dilanjutkan dengan melakukan proses data cleaning. Pada dasarnya proses data cleaning adalah kita melakukan pengecekan missing value, outlier dan bad data pada data yang akan kita gunakan.
Pada saat mendapati bahwa data kita terdapat missing value ada beberapa hal yang bisa kita lakukan. Yang pertama adalah dengan menghapusnya, dan yang selanjutnya adalah mengisinya dengan mean, media, atau anda bisa melakukan generate data berdasarkan trend data sebelumnya.
Masalah selanjutnya yang muncul adalah outlier, outlier secara sederhana adalah sebuah data yang menyimpang dari keteraturan. Outlier dapat diacuhkan jika jumlahnya sedikit karena dinilai tidak berpengaruh pada proses analisa. Tetapi jika jumlahnya banyak anda perlu melakukan pekerjaan tambahan dalam menyelesaikannya misalnya dengan menggunakan model yang kuat dengan outlier, dan melakukan tranformasi. Untuk bisa mendeteksi outlier anda bisa menggunakan visualisasi boxplot.
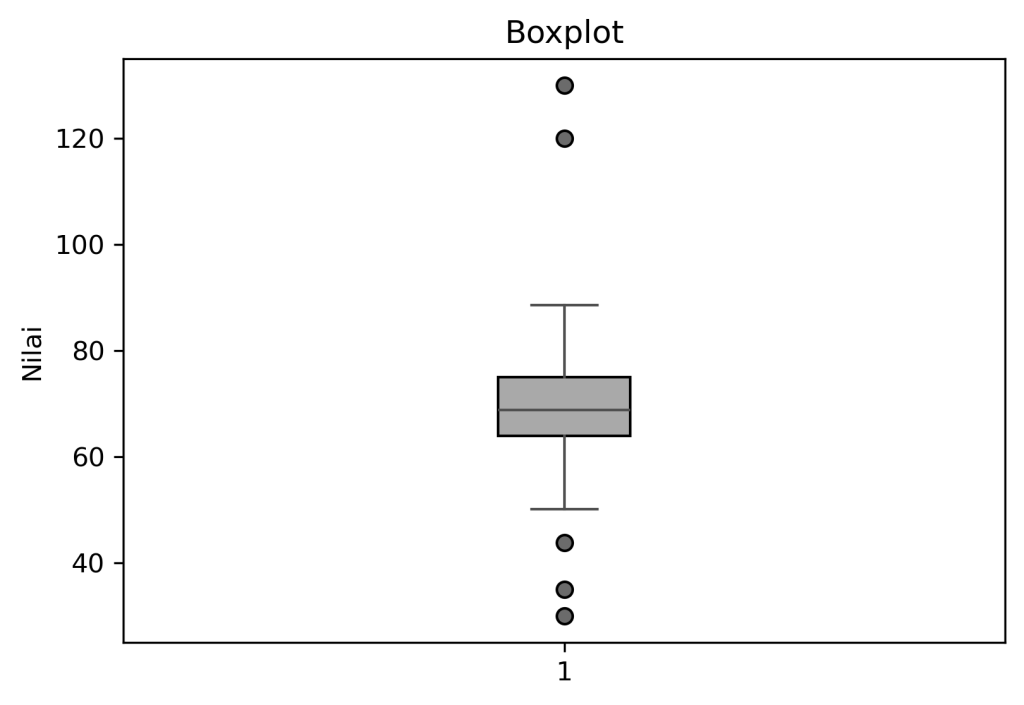
Yang terakhir adalah bagaimana treatment bad data. Bad data yang saya maksud adalah sebuah data yang sudah anda bersihkan dari missing value dan outlier tetapi masih menyimpan data yang tidak dibutuhkan untuk analisa. Hal yang bisa anda lakukan adalah melakukan standarisasi penulisan data, sehingga data yang dihasilkan konsisten. Dan melakukan filtering, yaitu dengan membuang data data yang tidak perlu.
Manipulating data
Manipulating data merupakan kegiatan yang bertujuan untuk mengolah / mentransformasi data sesuai dengan tujuan penelitian agar dihasilkan sebuah analisa yang optimal. Data yang sudah bersih setelah melalui proses data cleansing bisa lanjut ketahap berikutnya.
Ada beberapa metode dalam melakukan manipulating data berikut merupakan beberapa diantaranya. Filtering data, grouping, join table, dan membuat kolom baru. Tetaapi ingat bahwa tidak semua metode harus digunakan dalam melakukan manipulating data, sesuaikan dengan tujuan penelitian anda.
- Filtering = Merupakan metode pemilihan data sesuai dengan kebutuhan (misalnya, dari 1000 data anda hanya membutuhkan data customer dengan umur diatas 25 tahun)
- Grouping = Merupakan metode pengelompokan data lalu dihitung statistiknya.
- Join table = Jika terdapat data yang sama tetapi terdapat pada baris yang berbeda anda bisa menggunakan join table untuk menggabungkannya.
- Membuat kolom baru = Anda membuat kolom baru sesuai dengan kebutuhan (misalnya, anda membutuhkan data umur costomer setelah ditambahkan 5 tahun)
Rescaling
Jika kita bekerja dalam membangun sebuah model machine learning, terkadang ada beberapa model yang sensitif dengan perbedaan input data yang kita miliki. Kita perlu melakukan metode rescaling untuk menghasilkan sebuah model yang optimal. Rescaling merupakan sebuah upaya untuk mengubah skala nilai dalam dataset ke range tertentu tanpa mengubah pola atau distribusi utamanya.
Misalnya anda memiliki data berat badan dan tinggi badan pada sebuah perusahaan, dengan dua satuan yang berbeda yaitu cm dan inci. Jika kita memiliki fitur dengan skala yang berbeda, maka beberapa algoritma machine learning dapat menjadi bias terhadap fitur dengan nilai yang lebih besar. Oleh karena itu, diperlukan rescaling.
| Nama | Berat (kg) | Tinggi (cm) | Tinggi (inci) |
|---|---|---|---|
| A | 50 | 160 | 63 |
| B | 70 | 170 | 67 |
| C | 90 | 180 | 71 |
Untuk bisa melakukan rescaling pada umumnya menggunakan metode min-max. Berikut merupakan rumus dari min-max. Setelah dimasukkan rumus ini makan table akan berubah menjadi seperti berikut:
| Nama | Berat (scaled) | Tinggi cm (scaled) | Tinggi inci (scaled) |
|---|---|---|---|
| A | 0.00 | 0.00 | 0.00 |
| B | 0.50 | 0.50 | 0.50 |
| C | 1.00 | 1.00 | 1.00 |
Setelah melakukan rescaling maka model akan menganggap data lebih fair. Ada beberapa model yang sensitif dengan gap yang terlalu besar antara lain KNN, SVM, dan clustering. Anda bisa menggunakan metode rescaling jika data yang anda miliki memiliki fitur dengan skala yang sangat jauh.
Dimensionality reduction
Kadang tuh data terlalu berat, pernah ngga si kalian lakuin data visualisas. Terus ngerasa kayaknya polanya udah kebaca dengan data sebesar 70% aja deh. Untuk masalah seperti ini, kalian bisa menggunakan metode Dimensionality reduction. Jadi secara definisi dimentionality reduction merupakan metode pengurangan fitur/variable dalam dataset, tetapi tetap mempertahankan informasi pentingnya. Atau gampangnya kaya, kita tuh mau potong data yang ngga penting dan disisakan yang penting – penting aja.
Tujuan dari dimensionality reduction itu membuang noice data yang tidak diperlukan, supaya model yang dihasilkan lebih cepat, menggurangi overfitting (model terlalu pintar, dalam artian hanya pinter dengan dataset yang sudah dilatih tetapi jika diuji dengan dataset lain model akan rawan salah).


Demikain penjelasan dari saya bagaimana cara mengerjakan pekerjaan data science seperti bagaimana proses penyiapan data hingga menyajikannya. Semoga bisa menjadi tambahan informasi bagi pembaca. Jika ada yang ingin melihat tulisan saya yang lainnya anda bisa masuk ke section blog.
Warm regrads
Febrian
Baca juga: The catalyst