
Cancer is one of the deadliest diseases. We often hear about people dying from this disease. I myself have lost a friend to this disease. On this opportunity, I will try to create machine learning that detects cancer.
Given that my educational background is in chemical engineering, I apologize if there are still many imperfections in this project, but I will continue to strive to learn as much as possible. If you have any suggestions, please email me. I greatly appreciate any improvements you can offer.
Background of the problem
I took the data to be analyzed from Kaggle. The dataset contains pathological images of various cell photos infected with cancer cells and not infected with cancer cells. There are several medical terms that are unfamiliar to the general public. I will explain them one by one first.
Histopathology
Histopathology is a procedure that involves examining whole tissue samples taken through biopsy or surgery under a microscope. This examination is often aided by the use of special staining techniques and other related tests, such as the use of antibodies to identify various tissue components in the body.
If you remember high school, we were once asked to observe plant cells using a microscope. And if we wanted more detail, we could add a dye. Histopathology is basically like that: scientists take samples, stain them, and store the results of their observations as a dataset. We will use this dataset to create machine learning. Here is an example of a sample dataset that will be analyzed.
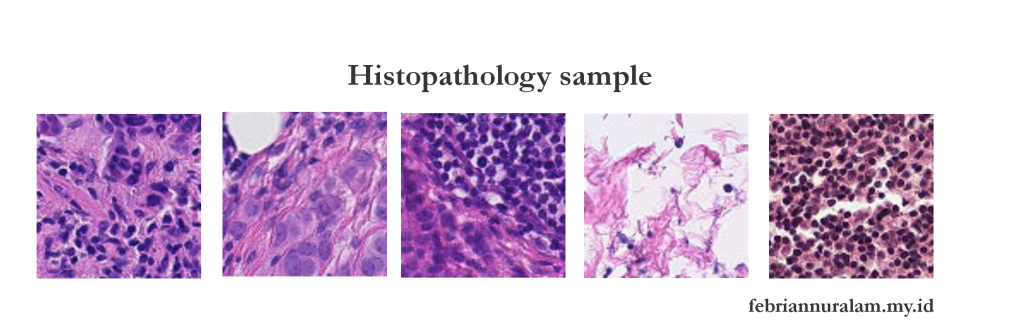
The data provided is taken from observations of lymph nodes that have been stained with hematoxylin and eosin (H&E). Hematoxylin and eosin (H&E) is a staining method commonly used to color cells so that they can be observed under a microscope.
The staining technique using hematoxylin and eosin is widely used because it can distinguish between the nucleus and cytoplasm in cross sections. Hematoxylin functions as a good nucleus stain and gives a blue-black color, while eosin functions as a cytoplasm stain and gives a pink color.
Lymphocyte
Lymphocytes are a type of white blood cell that fights foreign substances in the body, such as viruses, bacteria, and cancer cells. There are three types of lymphocytes, each with a different role. When the number of lymphocytes is too low or too high, it could indicate a specific disease.
Lymph nodes
Lymph nodes are part of the immune system that fight infections caused by bacteria, viruses, germs, and parasites. When an infection occurs, the nodes swell to signal the problem. Once the infection subsides, the nodes shrink on their own and return to their original size.
Dataset description
For the dataset I used this time, I took data from the Kaggle website. The analyzed data has the following specifications.
- This dataset consists of histopathological images, each with a resolution of 96×96 pixels.
- The label of interest is determined by the center region of the image (32×32 pixels). A positive label is assigned if this center region contains at least one pixel of tumor tissue, indicating the presence of cancer.
- This data set is designed to support full convolutional models without requiring zero-padding. This ensures that the model’s behavior remains consistent when scaled up to analyze whole-object images.
Without further ado, please read my report on machine learning that I have created.
Discussion
I trained the data using Python and the convolutional neural network (CNN) method. The training process took approximately nine hours. Here are the results of the machine learning model I built.
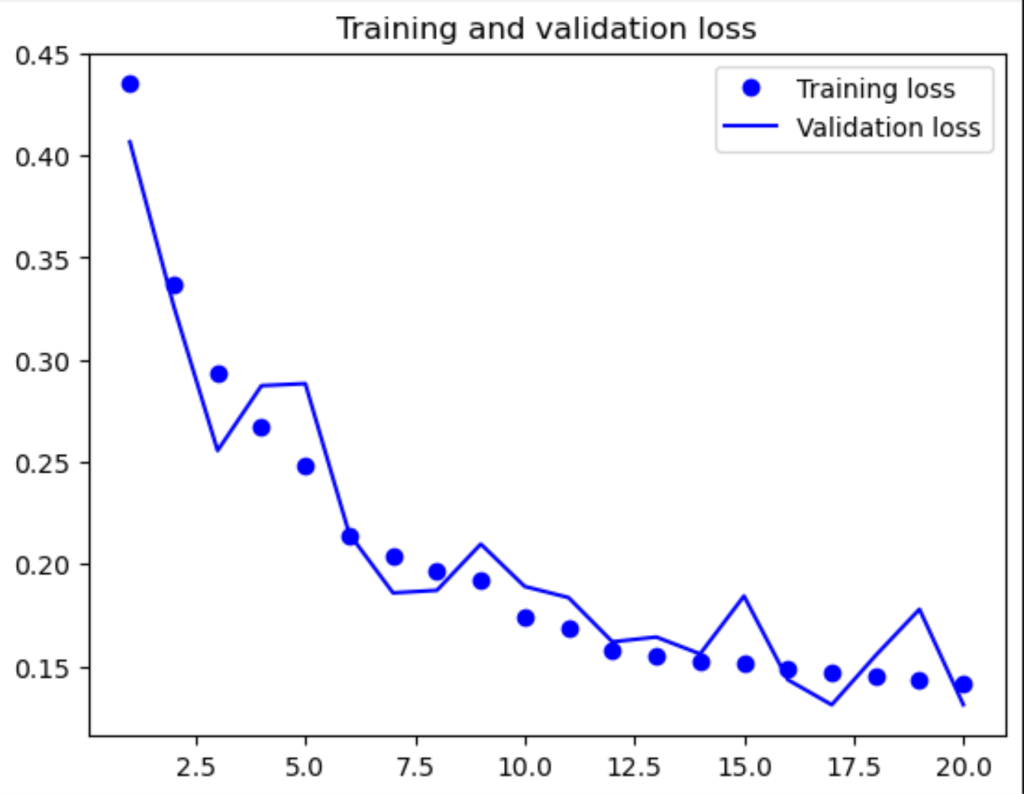
Training and validation loss
The training and validation loss are the error rates of the model when tested using data that was not included in the training. The lower the validation loss value, the better the model is. The graph shows a downward trend until epoch 20, where a validation loss of 0.165 is obtained.

Training and validation accuracy
The training and validation accuracy is the percentage of prediction accuracy of the model when tested using validation data. The higher the validation accuracy, the better the model will be. It can be seen in the graph on the right that in the first epoch, the model obtained low validation accuracy and continued to increase to 0.94, or it can also be said to have an accuracy of 94%.
That concludes our discussion on creating machine learning using the CNN method. Thank you very much for reading to the end. If you want to see the code I made, you can view it on my GitHub account.
Warm regrads
Febrian